Many people reading this will be familiar with basic error detection and error correction. RS232, the serial line transmission protocol, can use one 'parity bit' which will be set according to the sum of the other bits in a frame. If it doesn't add up when it's received, the frame is discarded. If there are two errors in a frame, they will go unnoticed, but hopefully that will be very rare. Parity in RS232 provides no way to recover the correct data.
RAID 5 is a common error correction system. If a particular disc in a RAID cluster fails, we can still recover the data on it from the other discs and the parity disc. However, we must know that a disc has failed, so RAID 5 would be layered on top of an error detection system (in this example, the CRC checks implemented inside the disc). This makes RAID 5 an erasure code; it corrects data which is known to be bad, or erased.
The trouble is, parity based schemes don't extend very well; they can only cope with one bad block of data; you can't just add an extra parity bit on and expect to cope with two failures. Most schemes are a tradeoff between data integrity and overhead (the extra disc in the RAID array), but you can't where to place that tradeoff, except at a few granular points.
Hamming codes
Hamming codes are slightly more robust than simple parity. Hamming codes have several parity bits, each of which covers a different part of the message. The simplest (meaningful) Hamming code is one with three bits of parity for four data bits. The parity bits are interleaved with the data, like this:
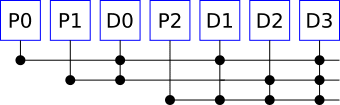
Parity bit 0 contains the parity for all the even-numbered bits in the sequence, including itself. That's not the even-numbered data bits, but the even numbers of all the arranged parity and data bits. Parity bit 1 contains the parity for bits 1, 2, 5 and 6, and bit 2 for bits 3, 4, 5 and 6.
Now each bit in there is covered by a unique combination of parity bits. When the receiver gets this, it will recalculate the parity bits and look for disagreement. If parity bits P1 and P2 disagree, then there is probably a fault in the transmission of D2, so we can flip that and continue. If only P1 disagrees, there there was probably a fault in the transmission of P1, but we don't need the parity bits to be corrected, so we can ignore that.
A Hamming code can not only detect but correct any single error. If you now add one more parity bit you can detect (but not fix) up to two bit corruptions.
This particular Hamming code (3 parity, 4 data) is not particularly common as it uses a large ratio of parity to data bits, but when you scale up, that ratio gets better - 5 parity bits can cover 26 data bits, for example.
So now we've got a bit more redundancy. And this is good enough for cases where errors are quite rare, like in computer RAM. ECC RAM usually uses Hamming codes, which is usually good enough.
Reed-Solomon Codes
Reed-Solomon error correction allows more flexibility. By adding n extra symbols (think of bytes as symbols, if that's easier), a Reed-Solomon code can detect up to n errors in a set of symbols, and it can correct n/2 of those symbols. If it's used as an erasure code - that is, we know which symbols are missing or corrupt - then it can repair n of them. The basis of a Reed-Solomon code is that any sequence can be converted into a polynomial and back again. So, for the ASCII values of "Hello", I make points at increasing x coordinates:
(0,72) (1,101) (2,108) (3,108) (4,111)
With a bit of maths, we can find a polynomial equation which will pass through all those points (when the points are rounded to the nearest integer):
y = -0.20833 * x**4 + 3.75 * x**3 - 20.79167 * x**2 + 46.25 x + 72
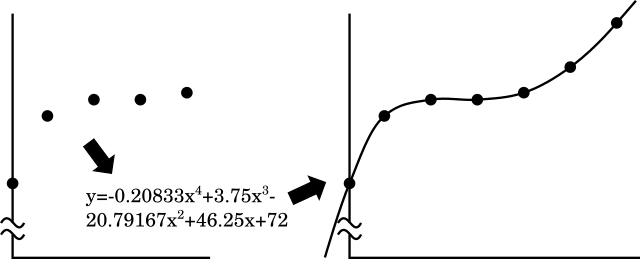
Now all that's necessary is to calculate some extra points, so for the x values 5 and 6, I calculate the y value and get (5, 122) and (6, 141). I then transmit "72 101 108 108 111 122 141". The receiver can reproduce the polynomial above given any five of those values, and from that, reproduce the original data. You can then add as many extra points as you wish; on a really noisy channel, you might send more than there were in the original message.
This is a vast simplification. Point 6 is already outside the range of ASCII symbols and at some point will drop below zero, so modulo arithmetic must be used, complicating the search for the polynomial expression. The original Reed-Solomon system transmitted the exponents of the polynomial, rather than the values of it. Also, I haven't even started to explain how it is used for error detection.
Repair costs, and locally repairable codes
I have a RAID5 array at home which works well, and the time it will take to repair when a disc fails is not really a concern. In a large datacentre, however, storage failures will be routine, and so data which is split between several nodes in a network will be constantly under repair. Previously our tradeoff was between space and safety, but now we have a third item, the cost of repairs, to consider, and it is often at odds with one of the other two.
If I have a 10GB video file, stored over 10 nodes over a wide-area network, and one node fails, how much network bandwidth do I need to use to return to the original safe level of redundancy? If I had used a Reed-Solomon code, then I will actually need to copy 10GB, the whole size of the original file, to recreate the failed node. By contrast, if I had striped and replicated that video file, each node would have one of two replicas of a 2GB chunk, and I would only need to copy one other node's 2GB of data to recreate the failed node. Replication uses more storage space, but less repair bandwidth.
There are approaches which can find compromises between these, which are locally repairable codes. They are too complicated to explain in a blog article, but I can just make you aware of two academic papers for further reading. The problem is explained better by Network Coding for Distributed Storage Systems, and a potential solution by Locally Repairable Codes.
Other Content
- Codethink has achieved ISO 9001:2015 accreditation
- Outreachy internship: Improving end-to-end testing for GNOME
- Lessons learnt from building a distributed system in Rust
- FOSDEM 2024
- Introducing Web UI QAnvas and new features of Quality Assurance Daemon
- Outreachy: Supporting the open source community through mentorship programmes
- Using Git LFS and fast-import together
- Testing in a Box: Streamlining Embedded Systems Testing
- SDV Europe: What Codethink has planned
- How do Hardware Security Modules impact the automotive sector? The final blog in a three part discussion
- How do Hardware Security Modules impact the automotive sector? Part two of a three part discussion
- How do Hardware Security Modules impact the automotive sector? Part one of a three part discussion
- Automated Kernel Testing on RISC-V Hardware
- Automated end-to-end testing for Android Automotive on Hardware
- GUADEC 2023
- Embedded Open Source Summit 2023
- RISC-V: Exploring a Bug in Stack Unwinding
- Adding RISC-V Vector Cryptography Extension support to QEMU
- Introducing Our New Open-Source Tool: Quality Assurance Daemon
- Long Term Maintainability
- FOSDEM 2023
- Think before you Pip
- BuildStream 2.0 is here, just in time for the holidays!
- A Valuable & Comprehensive Firmware Code Review by Codethink
- GNOME OS & Atomic Upgrades on the PinePhone
- Flathub-Codethink Collaboration
- Codethink proudly sponsors GUADEC 2022
- Tracking Down an Obscure Reproducibility Bug in glibc
- Web app test automation with `cdt`
- FOSDEM Testing and Automation talk
- Protecting your project from dependency access problems
- Porting GNOME OS to Microchip's PolarFire Icicle Kit
- YAML Schemas: Validating Data without Writing Code
- Deterministic Construction Service
- Codethink becomes a Microchip Design Partner
- Hamsa: Using an NVIDIA Jetson Development Kit to create a fully open-source Robot Nano Hand
- Using STPA with software-intensive systems
- Codethink achieves ISO 26262 ASIL D Tool Certification
- RISC-V: running GNOME OS on SiFive hardware for the first time
- Automated Linux kernel testing
- Native compilation on Arm servers is so much faster now
- Higher quality of FOSS: How we are helping GNOME to improve their test pipeline
- RISC-V: A Small Hardware Project
- Why aligning with open source mainline is the way to go
- Build Meetup 2021: The BuildTeam Community Event
- A new approach to software safety
- Does the "Hypocrite Commits" incident prove that Linux is unsafe?
- ABI Stability in freedesktop-sdk
- Why your organisation needs to embrace working in the open-source ecosystem
- Full archive