Background
Historically, software components with a safety-related role have been expected to be low size (in terms of lines of code) and complexity, and were commonly developed from scratch for a specific purpose and system. In this sense, they were not dramatically different to electronic components, and so it made sense to treat them in a similar way, applying similar functional safety principles.
These principles have historically been understood as requiring deterministic behaviour for such software; that is, the software design should enable us to predictably determine what the software will do in a given circumstance, so that the safety implications of that behaviour can be clearly understood, and either controlled or mitigated.
Modern software-intensive systems, typically involving a multi-core microprocessor and a range of inputs and outputs, present a very different set of challenges:
- They may be orders of magnitude larger than the software components historically used in safety-critical systems
- Most of the code is pre-existing and developed with re-use in mind, often provided by a large number of common dependencies
- They make extensive use of open source software, which is developed without many of the formal software engineering practices that safety standards expect
- There is an implicit assumption that software will evolve, potentially changing many times over the lifetime of a system, to address bugs and add new features or enhancements
- They may make use of AI/ML models, which mean that a system's behaviour cannot be validated against a fixed, deterministic specification
- They use multi-tasking operating systems, which also exhibit non-deterministic behaviour, as they adapt to unpredictable internal stimuli from processes executing in parallel
The scope and complexity of some safety-critical applications under development are outpacing the ability of existing safety-certified software solutions to deliver. Increasingly, such applications are being developed using technology that has been developed with open source software in non-safety contexts, which means that product developers are confronted with two equally daunting challenges: (1) adapt the technology to run on a safety-certified platform based on a Real-Time Operating System (RTOS), which may have a radically different performance profile and none of the existing dependencies, or (2) apply safety standards to open source software, which deviates markedly from 'traditional' models of the software engineering lifecycle. The second option is the focus of initiatives such as ELISA, which explores the challenges of using Linux for safety critical systems.
A new approach
Codethink have been exploring these challenges for several years, both as a contributor to ELISA and Trustable, and in the course of our work with customers in the automotive industry. We have been supported on this journey by expert consultancy from Exida, a world-leading authority on safety certification.
In order to make safety-related promises about the behaviour of systems running complex software on multi-core microprocessors, including pre-existing open source software such as Linux, we believe that a new approach to software safety will be required, which:
- Can be applied to a huge body of pre-existing code, within a justifiable cost and time frame
- Can handle a very high rate of upstream, development and integration change
- Recognises the unique characteristics of modern software components in comparison with other system elements
This article proposes a new approach, developed with operating systems based on Linux in mind, that seeks to address these objectives.
Note that the activities described are expected to form part of an iterative process for a given system, with each iteration refining the system's specification and associated safety analysis, and the measures required to verify and validate it.
OS responsibilities
Our first challenge is to specify, with sufficient clarity, what we need Linux to do as part of a system, and how these responsibilities are relevant to the safety-critical elements of that system.
For a general-purpose operating system component like the Linux kernel, which has evolved to support a very wide variety of hardware and applications, the potential scope of its responsibilities may be very large. However, not all of this functionality will necessarily be related to the system's safety-critical applications; depending on the nature of the responsibilities, we may be able to limit our specification to a subset.
This task may still be non-trivial, however, because Linux, in common with most free and open source software (FOSS), lacks a formal specification of its design and the goals that inform it. A wealth of technical information is available, and anyone is free to examine its source code in order to understand more, or read kernel developer mailing lists to understand the decisions behind changes. However, the Linux development process does not include the formal documentation of requirements, architecture and design.
In part, this reflects the nature of Linux: it does not have a specific and formally circumscribed purpose, but is instead iteratively adapted, refined and extended to address an ever-expanding set of purposes and applications, by anyone who is willing to contribute. Linux is extremely configurable by design, which means that one system deployment including Linux may differ radically from another, even if they both share a common hardware platform.
In this first stage, therefore, we must document both the specific system context in which we intend to use Linux, and the subset of functionality that we expect it to provide in that context.
Define system context
The system context for the OS must encompass all of the components that will, together with the Linux kernel, provide the operating system services. It must also include the kernel configuration used to construct the kernel, as this will determine which features are available, and how they behave. It must also include the system hardware components, most notably the CPU architecture and any components that will be used by the system's safety application(s).
Define OS functions
Next, we must define the functions that the OS (including Linux) will provide in this system context. Because we are primarily concerned with the role of the OS with respect to safety, we can limit this subset to the functionality that the OS provides for safety-critical applications as part of the system. However, we may need to consider a wider scope of functionality if applications without a safety-related function are expected to run in parallel on the system.
Define control structure
The components of the system that are involved in these functions are then specified in control structure diagrams, which describe the system as a hierarchy of control feedback loops. The OS, and the components that it interacts with are controllers in this hierarchy, and their interactions are represented as control actions (down arrows) and feedback (up arrows). Controllers may represent hardware or software components, and may be an abstraction of multiple components or categories of components.

Safety requirements
Our next challenge is to specify a set of detailed safety requirements for the OS. We will accomplish this by using STPA to perform a top-down hazard analysis of the system defined in the previous activity. For more information, see the STPA Handbook
Define system-level losses and hazards
A critical first part of this analysis is to identify and understand hazards in the context of the wider system. How might failures or unintended behaviour of the system as a whole lead to losses? As discussed in a previous article, we cannot understand a component's responsibilities with regard to safety without examining its role for a particular system, because the losses that we are trying to prevent, and the hazards that may lead to them, will be specific to that system.
At this stage we also identify system-level constraints, which are system conditions or behaviours that need to be satisfied to prevent hazards; they may also define how to minimise losses if hazards do occur. These are defined at the level of the overall system incorporating the OS, not the OS itself.
Identify potential hazards involving the OS
Hazard analysis is performed using the control structure diagrams created in the previous stage, as part of our definition of the system and the specific responsibilities of the OS.
The system conditions that can lead to system-level hazards may be specific to the OS (e.g. handling of hardware failures), but may also relate to the behaviour of other system components (e.g. a safety application's handling of failures reported by the OS). In order to identify these causes, which STPA calls unsafe control actions (UCAs), we examine how interactions involving the OS may lead to the system-level hazards identified in the previous step. Further analysis of these produces loss scenarios, which describes the causal factors that can lead to the UCAs and the associated hazards.
This analysis should focus on the overall responsibilities of the OS and its
interactions with other components at its boundaries (i.e. via kernel syscall
interface or equivalent), not the internal logic of the OS. We may need to
examine some of that internal logic in order to form an understanding of the
behaviour, but it is assumed that these internal details will not need to be
referenced in UCAs in most cases.
Specify constraints required to prevent these hazards
Constraints are specific, unambiguous and verifiable criteria that are applied to the behaviour of either the system as a whole, or of a specific controller in the control system hierarchy, in order to prevent a hazard. Controller constraints are derived directly from the UCAs and loss scenarios identified in the previous step.
Constraints may be implemented in many ways: design features of the OS, external safety mechanisms such as a hardware watchdog, offline verification measures applied during development or software integration (e.g. tests, static analysis rules) or online verification measures implemented by another software component (e.g. a monitoring process).
Note that these constraints are not confined to the OS. Some may already be fulfilled by aspects of the OS design; others may require the addition of a new feature as part of the OS, or an external safety mechanism. However, many may need to be applied as requirements on the development processes or design of safety applications, such as static analysis rules that must be applied when verifying application code, or system-level testing that must be performed to validate an application's use of the OS, or the behaviour of the hardware.
Historical and regression testing
To ensure that the OS provides the expected behaviour required by safety applications, we must develop a set of tests. It may be possible to re-use or adapt existing tests developed for Linux for some of these.
Tests should be system-level wherever possible, using the external interfaces of the OS, as this is the most efficient way to verify behaviour on an ongoing basis, and ensures the long term relevance of tests. Because of the nature of Linux, the stability of internal component logic cannot be guaranteed, but the kernel development community has an explicit 'golden rule' ("Don't break userspace!") that should guarantee the stability of its external interfaces and associated behaviour.
Some functionality may require different or additional verification strategies, where a constraint cannot be verified at OS system level, but these should be the exception. An example might be a static analysis rule to check that kernel access to user memory follows the correct protocol, as discussed in a previous article.
Regression testing
Since we explicitly expect the OS components to change over the lifetime of the system, we need regression tests to verify that current OS components satisfy our safety requirements. These will correspond directly to OS design constraints identified during hazard analysis: they exercise potentially unsafe behaviours and verify that the required behaviour is exhibited. Statistical measurement of test results (negative fault, negative detect) will be used to provide evidence to support a safety case; where tests fail, additional impact analysis will be required.
Historical testing
Because we do not have a formal functional specification for the OS, we
also need to provide evidence that the expected behaviour has been present and
stable over time. To accomplish this we repeat regression tests using historical
versions of OS component (e.g. Last 1000 released Linux kernel versions) to
provide evidence of the expected functionality over time. Test failures will
be investigated to help refine existing tests and analysis. These may reveal
hazards that were not identified in original analysis, or provide examples to
inform fault injection and stress testing (see below).
Statistical analysis and models
We will also use statistical models to provide increased confidence in tests, or establish a level of confidence in test coverage when complete certainty is not feasible. Examples include:
- Identifying a representative set of tests, where a comprehensive set is not possible or practical
- Using a stochastic model to show that non-deterministic behaviour falls within expected bounds
- Measurement of test results (negative fault, negative detect) and other test characteristics (e.g. execution time), to identify patterns and anomalies
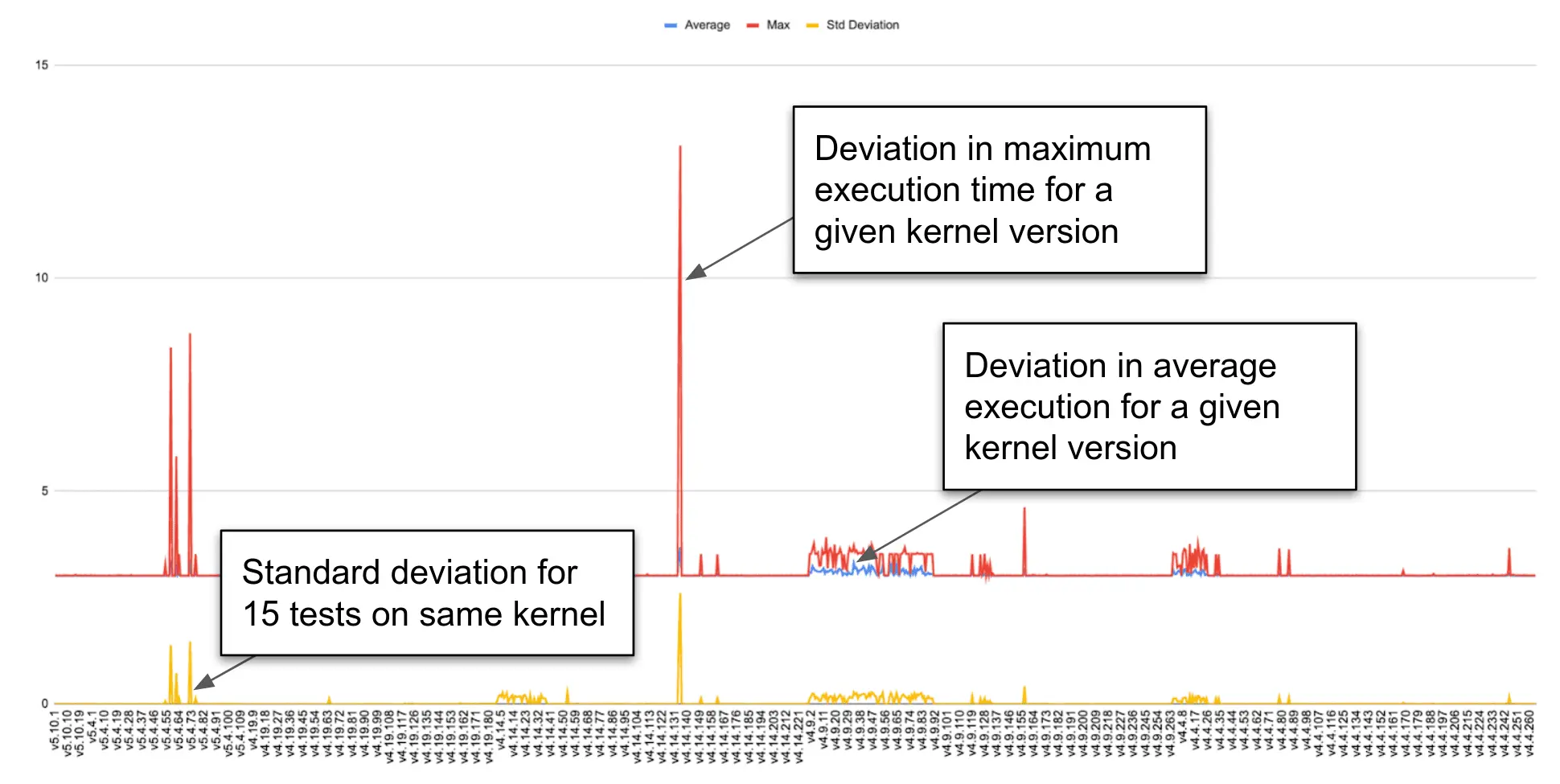
Confidence in test results can be increased by examining them from a different angle, and challenging assumptions in order to avoid false confidence. Simple pass/fail results may conceal an unidentified issue or hazard; examining other characteristics of tests, such as the execution time or CPU load, may help to reveal these, or to identify flaws in tests or test infrastructure that are distorting or concealing results.
Fault injection and stress testing
Simply confirming the expected functionality is not sufficient, however: in order to have confidence in the safety of a system, we need to validate its behaviour when things go wrong, or behaviour deviates from the expected path.
Fault injection
To test this we will use fault injection strategies, constructing alternate versions of the software that deliberately violates the expected behaviour. The intention here is to provoke or simulate the hazards identified during analysis, in order to validate the safety measures developed to mitigate these hazards (e.g. confirm the effectiveness of tests). These are false positive checks: we introduce faults and make sure they are detected or mitigated; we clear faults and make sure they are no longer reported.
This strategy is intended for use with a complete system, not only for testing the OS in isolation. They can be used to validate safety mechanisms provided by external components, verify the handling of OS-related faults and other hazards by safety applications, and facilitate the validation of overall system safety measures in the final product.
Where possible, fault injection should be accomplished by simple code changes to
software as deployed (e.g. kernel patches applied during construction); this
means that the OS can be used in system testing without special preparation.
Where appropriate, faults may also be injected via a test process (e.g.
simulating interference by a ‘rogue’ process). In some cases, faults may need to
be injected using custom kernel modules, and triggered via an ioctl interface,
either randomly or via a test fixture. This approach should be the exception,
but may be necessary for fundamental functionality, where a simple change would
prevent system initialization.
OS fault-injection should be included as a matter of course in system-level smoke tests, perhaps by periodically using an OS image with randomly selected fault(s). This serves to validate OS functional tests and uncover gaps in application or other system components.
Stress testing
Safety functionality may also be compromised by system load or interference from other applications running in parallel. We can use existing tools such as stress-ng and targeted tests to simulate system conditions and/or interference from other processes. These tests will need to be tailored for a given system, as the nature and scope of other applications (both safety and non-safety) on a system will vary, but it should be feasible to define a generic set of tests, which can be extended and refined over time.
Hazard analysis will help to inform these tests, by identifying specific system conditions or sources of interference. Results from historical testing and statistical analysis may also suggest further tests.
Deterministic construction
Construction is the foundation for the key engineering processes that underpin all of this analysis, verification and validation. This includes the tools, processes and inputs used to build and verify the system, the build and test environments in which these processes are executed, and the configuration and change management of these resources.
We can use predictable characteristics from construction to support verification and impact analysis. Binary reproducibility of system artifacts and toolchain components enables cross-validation of these elements. We can use a previously-validated system binary, which was output by the toolchain, to verify a new revision of that toolchain. If a system binary changes when no source, tool or configuration has been changed, this may indicate an uncontrolled configuration file or cached dependency. We can also use binary reproducibility to verify impact analysis for OS: if we compare output binaries with a previous version, and a source change has no effect on the output binary, then tests do not need to be repeated.
A deterministic construction process enables impact analysis with very fine granularity. Using declarative construction definitions means that we have complete control over how components are constructed, and which inputs are used. This includes construction and verification tools and build dependencies as well as the system component source code. All of these inputs are managed in git repositories under direct change control; where these originate from 'upstream' open source projects, these repositories must be mirrored on infrastructure that we control, to ensure that we have continuity of access and can detect anomalous changes.
We can then use an automated CI/CD process built on this foundation to drive safety processes and the evidence required to support a safety case. This includes provenance for all inputs and evidence of impact analysis for changes, traceability from requirement to test to test results, and configuration management aligned around the CI/CD process. This process should be designed to prevent manual fixes from bypassing verification and validation processes, or capture evidence of justification and approval for (rare) exceptions.
Next steps
There are some key assumptions made in this proposed approach, which can only be validated by applying it to a real example:
- The majority of testing must be performed at the OS boundary. Specifying and verifying the functionality at a lower level would be impractical, due to its scale and complexity, but the continued evolution of the kernel by the Linux community, without a formal specification to direct it, makes this infeasible.
- The hazard analysis that is used to derive safety requirements must also be focussed at this level, for the same reasons.
- The proposed testing and fault injection strategies need to provide sufficient evidence of safety integrity, in lieu of the formal specification material that is conventionally required by safety standards.
Codethink will be presenting this approach at the ELISA Workshop and look forward to discussing it with other ELISA contributors. It is shared as a work-in-progress and we would welcome feedback.
Download the white paper: Safety of Software-Intensive Systems From First Principles
In this white paper, Paul Albertella and Paul Sherwood suggest a new approach to software safety based on Codethink's contributions to the ELISA community and supported by Exida. Fill the form and you will receive the white paper in your inbox.
Related blog posts:
- Applying functional safety techniques to complex or software-intensive systems: Safety is a system property, not a software property >>
- About the University of Minnesota’s research: Does the "Hypocrite Commits" incident prove that Linux is unsafe? >>
Other Content
- Assessing the reproducibility workflow in freedesktop-sdk
- Deep Dive into Upstream RISC-V Boot Chain
- Porting an Automotive Operating System to RISC-V
- Understanding Codethink's IEC 61508 Mapping for the Eclipse Trustable Software Framework
- Resisting Hyrum's Law with Private Constructors in Python
- FOSDEM 2026
- Building on STPA: How TSF and RAFIA can uncover misbehaviours in complex software integration
- Adding big‑endian support to CVA6 RISC‑V FPGA processor
- Bringing up a new distro for the CVA6 RISC‑V FPGA processor
- Externally verifying Linux deadline scheduling with reproducible embedded Rust
- Engineering Trust: Formulating Continuous Compliance for Open Source
- Why Renting Software Is a Dangerous Game
- Linux vs. QNX in Safety-Critical Systems: A Pragmatic View
- Is Rust ready for safety related applications?
- The open projects rethinking safety culture
- RISC-V Summit Europe 2025: What to Expect from Codethink
- Cyber Resilience Act (CRA): What You Need to Know
- Podcast: Embedded Insiders with John Ellis
- To boldly big-endian where no one has big-endianded before
- How Continuous Testing Helps OEMs Navigate UNECE R155/156
- Codethink’s Insights and Highlights from FOSDEM 2025
- CES 2025 Roundup: Codethink's Highlights from Las Vegas
- FOSDEM 2025: What to Expect from Codethink
- Codethink/Arm White Paper: Arm STLs at Runtime on Linux
- Speed Up Embedded Software Testing with QEMU
- Open Source Summit Europe (OSSEU) 2024
- Watch: Real-time Scheduling Fault Simulation
- Improving systemd’s integration testing infrastructure (part 2)
- Meet the Team: Laurence Urhegyi
- A new way to develop on Linux - Part II
- Shaping the future of GNOME: GUADEC 2024
- Developing a cryptographically secure bootloader for RISC-V in Rust
- Meet the Team: Philip Martin
- Improving systemd’s integration testing infrastructure (part 1)
- A new way to develop on Linux
- RISC-V Summit Europe 2024
- Safety Frontier: A Retrospective on ELISA
- Codethink sponsors Outreachy
- The Linux kernel is a CNA - so what?
- GNOME OS + systemd-sysupdate
- Codethink has achieved ISO 9001:2015 accreditation
- Outreachy internship: Improving end-to-end testing for GNOME
- Lessons learnt from building a distributed system in Rust
- FOSDEM 2024
- QAnvas and QAD: Streamlining UI Testing for Embedded Systems
- Outreachy: Supporting the open source community through mentorship programmes
- Using Git LFS and fast-import together
- Testing in a Box: Streamlining Embedded Systems Testing
- SDV Europe: What Codethink has planned
- How do Hardware Security Modules impact the automotive sector? The final blog in a three part discussion
- How do Hardware Security Modules impact the automotive sector? Part two of a three part discussion
- How do Hardware Security Modules impact the automotive sector? Part one of a three part discussion
- Automated Kernel Testing on RISC-V Hardware
- Automated end-to-end testing for Android Automotive on Hardware
- GUADEC 2023
- Embedded Open Source Summit 2023
- Full archive