Professional sports organisations have been one of the earliest and highest profile adopters of Computer Vision (CV) technologies; with systems in use today considered accurate and reliable enough to replace or augment the referee's decision making.
This blog post details some research and development work Codethink conducted last year; building a low cost multi-camera sports tracking system. We specifically focus on camera space tracking on embedded platforms here, as well as running through some of the background and state of the art of Computer Vision.
Some Background
A Very Short History
The field of Computer Vision has been the focus of research for a wide range of specialists since at least the 60s. A lot of early thinking was driven by Artificial Intelligence researchers, who were quite optimistic that they would make significant progress in the field. However, many of the approaches proposed were impractical at the time, which led to specialised, mathematically rigorous approaches to a number of well specified problems.
A good example of a more traditional CV algorithm built on these mathematical methods is the Scale Invariant Feature Transform algorithm, which uses the differences across a family of scale spaces (progressively smoothed versions of the same image) to identify features that are, as the name suggests, invariant to scale. This algorithm can be implemented efficiently and is useful for tracking large sets of features across a series of images using stochastic methods. Applications include; stitching panoramic images together; and generating point clouds to feed into Bundle Adjustment based 3D reconstruction systems.

The general approach to CV has until recently revolved around taking these established algorithms and solutions and combining them into a functional system. The popular OpenCV library has historically been a collection of implementations of these algorithms that you can plug and play with. The problem with this approach is the applications developed require a significant amount of engineering to build and configure, and all of this configuration, tweaking and integration results in systems that are not robust to changes. Traditional CV is hard. This isn't to say that the techniques developed are obsolete.
The State of the Art
Over the last decade, a different tack has been outperforming traditional computer vision approaches in a number of benchmarks. Convolution Neural Networks, enabled by the development in parallel compute hardware (GPUs), have proven to be more accurate, general and robust in a wide range of problem spaces. The most striking example of this is in the image classification problem - in the simplest case, an application that can answer the question "is this a cat or a dog?" when presented with an image:

This is a very hard problem to solve with traditional approaches. You would have to manually identify what features are important when distinguishing a cat and a dog, and you would have to design a system that could extract those features from an arbitrary image and then perform some form of comparison against a baseline.
This is effectively the approach that all of the modern image classifiers and detection CNN network architectures take; they (i) codify what features are important to look for in an image, (ii) extract those features from an image and (iii) compare the feature against a baseline truth. However, the nature of neural networks means that the actual encoding of the information "what features make a dog/cat", etc., can be done automatically using generic tooling in a process called "training" - where you present the network with example, labelled data and use back-propagation and gradient descent to set the weights in the network and minimise a cost function.
A Note on CNNs
There obviously isn't space to go over in detail the theory behind Neural Networks (NNs) - an excellent resource to get the fundamentals is a book called Deep Learning. It's free, and the content is accessible.
However, it's interesting to discuss the nature of Convolution Neural Networks (specifically convolution layers), as they show how the line between traditional CV and more modern approaches is blurrier that it first appears.
A Neural Network is a set of matrices, each matrix describing an operation on the data fed into it. These matrices are called layers, and there are multiple types of layer - the type dictating how the values of the matrix determine the transformation of the data. The data typically flows through these matrices concurrently - known as Feedforward NNs. If there is feedback of data, then those networks are referred to as Recurrent NNs. This image gives you an indication of how a NN works in the example of image classification. As the data propagates through the network, each subsequent layer is able (after training) to pick up on more and more complex structures in the image.
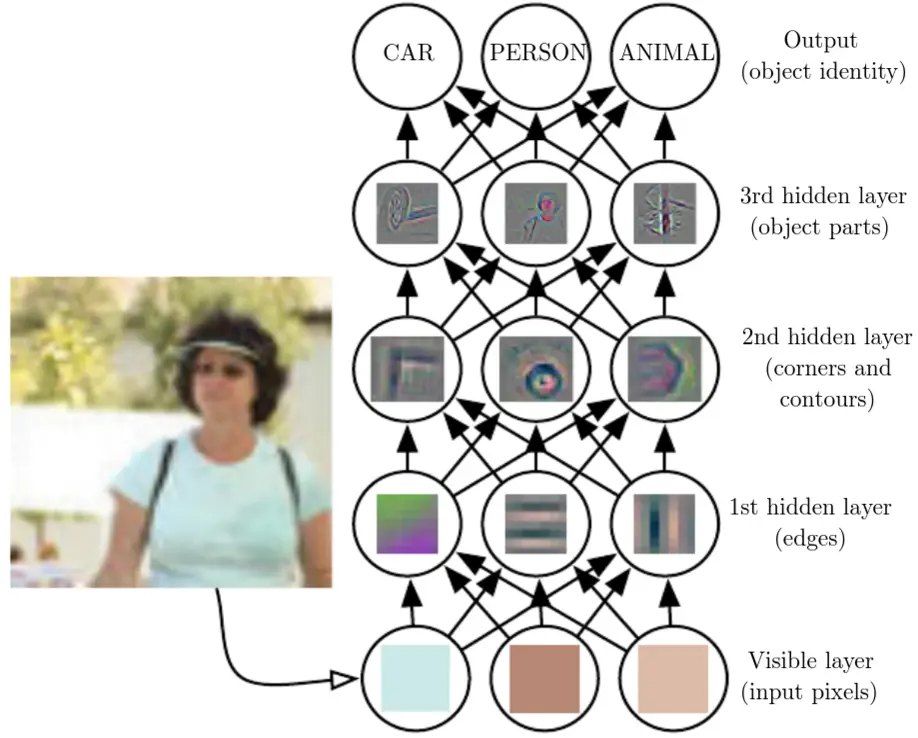 image from www.deeplearningbook.org
image from www.deeplearningbook.org
As with many great ideas, the power of this approach is that it's modular, and you can, in principle, build a network of arbitrary complexity. It's obvious/implicit in the inclusion of the word "neural" in the name that it's conceivable that when the hardware becomes sufficiently advanced, that you could emulate real neural systems.
The most important layer for a majority of image processing is the convolution layer. A convolution is a mathematical operation, and a convolution layer has many of the same properties of that operation, even though in practice it's not usually a strict convolution. A convolution layer is very similar to many "kernel" methods that are used in CV to extract features - where you scan a small "kernel" matrix over an image, performing matrix multiplication and generating a new image. A convolution layer can be thought of as this same process, but where the form of the kernel is learnable.
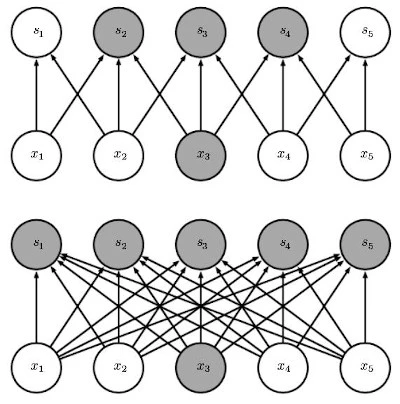 image from www.deeplearningbook.org
image from www.deeplearningbook.org
Since the matrix underlying the layer is much smaller than the data being fed in, it's very efficient at encoding the required filter properties - enabling larger networks than would otherwise be possible with denser layer types.
A number of CNN architectures have been developed over the last few years for detecting (identifying a given region of an image as an instance of a thing) a range of objects in an image. The Recursive-CNN (RCNN) network, for example, repurposes an object classifier and runs regions of the same image through the classifier multiple times to work out which bounding boxes have the least prediction uncertainty. On the other hand, the YOLO (You Only Look Once) network actually breaks down the image internally into a grid and only runs the image through the network once - resulting in lower inference times.
Camera-Space Tracking on a TX2
In 2019/20, Codethink worked to develop a system to track balls and players for one of our clients. Using multiple cameras, this system was designed from the ground up to have:
- low installation cost
- low complexity (maintenance cost)
- low latency
- scalable
We wanted to create a platform that provided access to high quality live tracking data at all levels of sport. By targeting low cost, low latency and low complexity, we imposed certain limits on the hardware and architecture. It was clear that the architecture would need to be minimally dependent on systems external to the stadium, and that the easiest way to make something scalable to different numbers of cameras and different configurations was to make the cameras do the tracking in camera space themselves.
The above requirements drove the selection of a camera with a high quality, high definition sensor, configurable optics and an onboard NVIDIA Jetson TX2 SoC. The cameras themselves would generate camera space tracking data, and forward that information (along with video streams) to a centralised triangulation system (which in our initial prototype was in fact one of the cameras themselves).
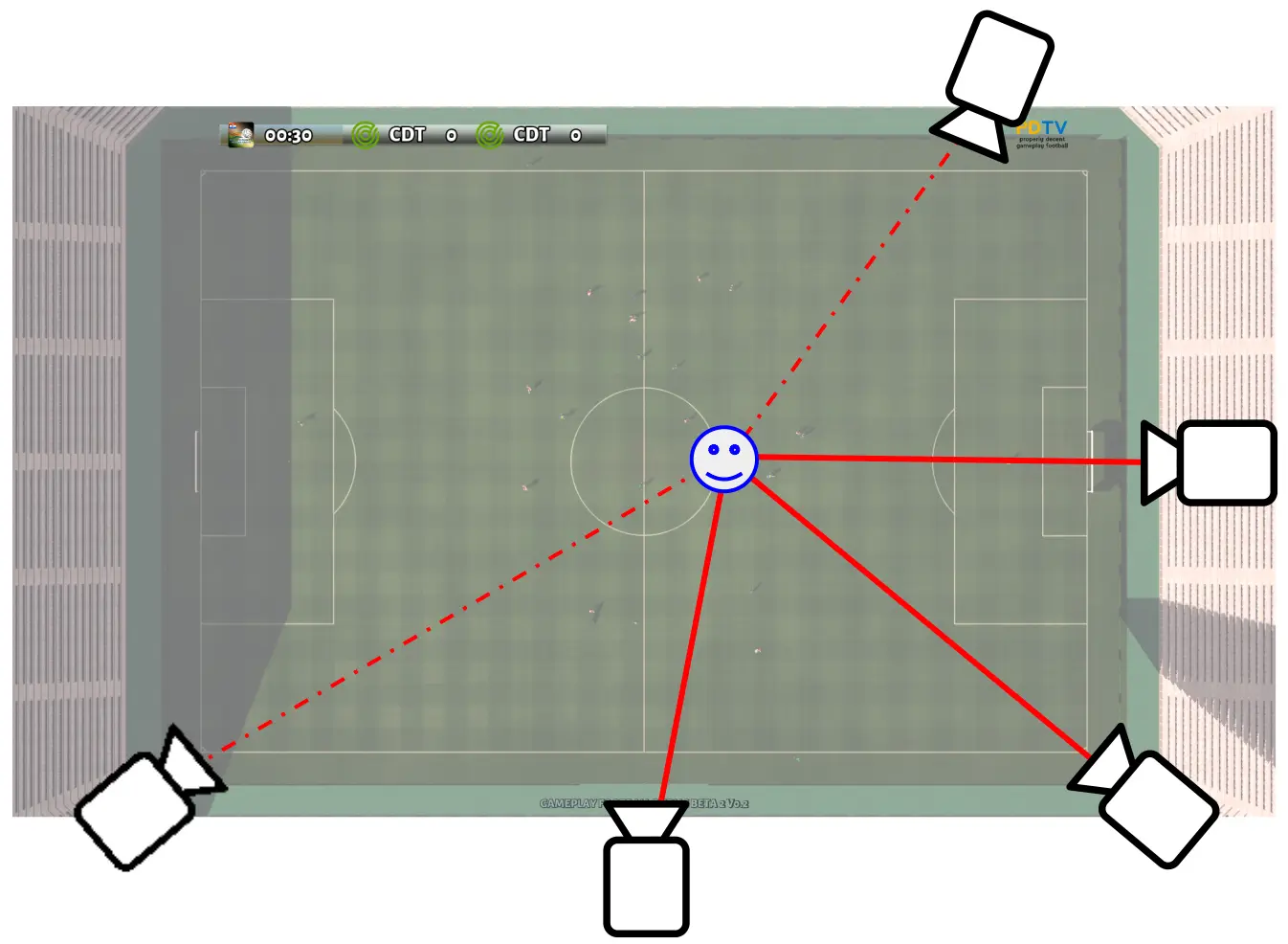
The initial work went into developing a robust RANSAC inspired triangulation algorithm for the 4+ camera problem, simultaneously generating a mapping of objects between the cameras and determining the 3D position of those objects by minimising back projection error.
We then explored some of the existing open source solutions to the embedded camera space tracking problem. We found that the best performing general tracking solutions at that time (for example) did not run at a practical frame rate on the resource constrained TX2s. Even running a CNN detector stand-alone, the best frame rates for detection were around 7 fps. This wasn't good enough considering the speed of the sport we were developing the system for.
This motivated us to develop our own hybrid system, that would combine the robustness and precision of a CNN and the efficiency of traditional CV techniques.
The driving idea was an attempt to emulate human vision - with a high bandwidth system processing movement and identifying regions of interest (peripheral vision) and a lower bandwidth system that can refine your idea of what those areas of interest actually are (visual gaze).
Implementation
To detect areas of interest, or candidate blobs, we use a combination of background subtraction, edge detection and kernel filtering. This process runs on the CPU with minimal overhead, such that the candidate blobs are generated at the target 30fps.
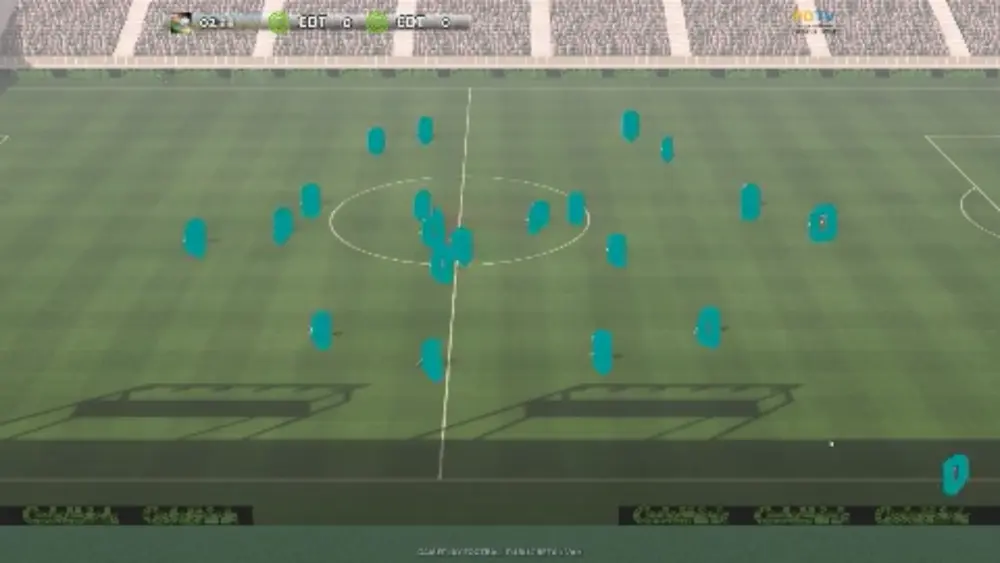
To further refine these blobs as and when possible, we employ a variation on the YOLOv3 network (a high accuracy, low inference time detection CNN).
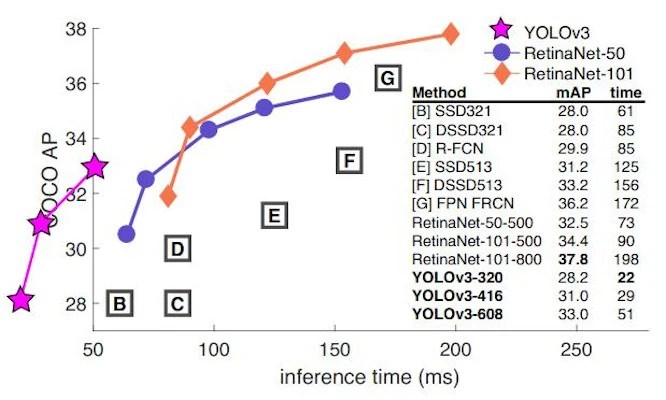 image from https://pjreddie.com/darknet/yolo/
image from https://pjreddie.com/darknet/yolo/
In order to stitch these two parallel processes together, we use the very powerful gstreamer framework to build a pipeline with branches feeding each of the subsystems. The system also performantly encodes and streams the video data over the network in a number of formats.
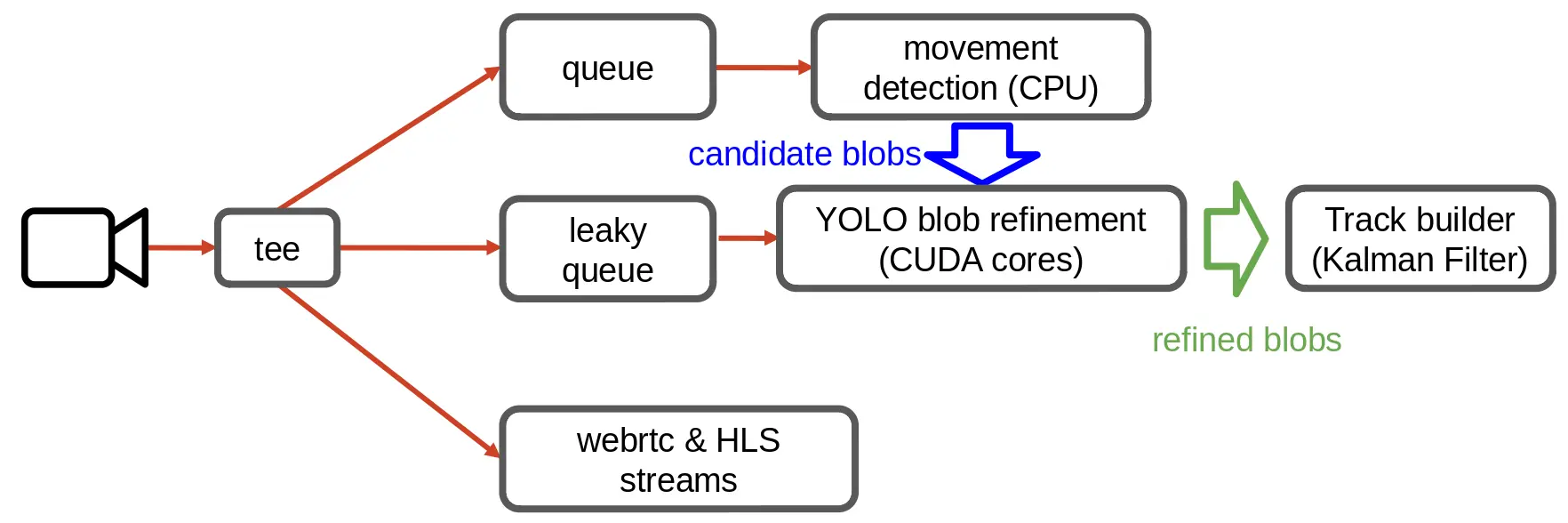
A set of blobs (bounding boxes with some additional metadata) are then passed between each sub-system, accumulating refinement information if the CNN is ready to accept a frame (otherwise the leaky queue drops frames), otherwise just forwarding the rough candidate blobs to the tracker - in which case the tracker uses historical data and some heuristics to determine the most likely refinement of the candidate blob.
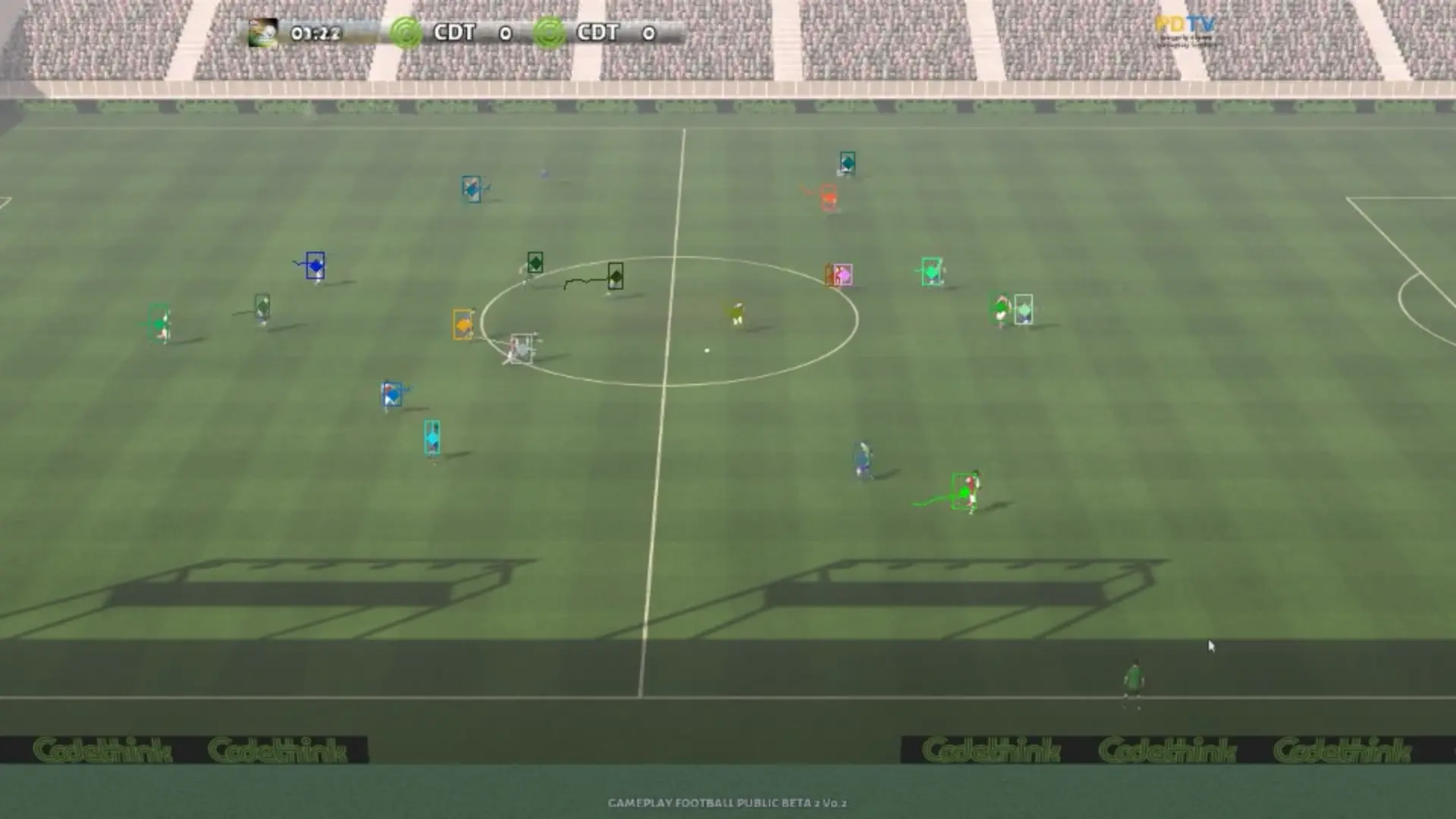
The results from our simple system are encouraging - we are able to track players with a high degree of bounding box precision at 30 fps. The tracker is entirely dynamic, and any fluctuations in inference time are smoothed out by the motion based candidate blob generation and the Kalman filtering of the tracks built from the blobs.
Future Work
Note that since we developed our system, a tracking system taking a very similar approach to ours (combining traditional tracking techniques and a YOLO object detection) has been released, with similar performance characteristics.
We are working on releasing an open source version of our work, and we will also look to benchmark our approach against these more recent developments.
References
Footage in the screen shots generated using Gameplay Football.
- SIFT
- Bundle Adjustment
- OpenCV
- Back-propagation
- Deep Leaning MIT
- Deep SORT
- SORT
- YOLO
- Kalman Filter
- FastMOT
Stay up to date on our latest news about embedded
Receive our most relevant Embedded stories in your inbox.
Related to the blog post:
Other Content
- Assessing the reproducibility workflow in freedesktop-sdk
- Deep Dive into Upstream RISC-V Boot Chain
- Porting an Automotive Operating System to RISC-V
- Understanding Codethink's IEC 61508 Mapping for the Eclipse Trustable Software Framework
- Resisting Hyrum's Law with Private Constructors in Python
- FOSDEM 2026
- Building on STPA: How TSF and RAFIA can uncover misbehaviours in complex software integration
- Adding big‑endian support to CVA6 RISC‑V FPGA processor
- Bringing up a new distro for the CVA6 RISC‑V FPGA processor
- Externally verifying Linux deadline scheduling with reproducible embedded Rust
- Engineering Trust: Formulating Continuous Compliance for Open Source
- Why Renting Software Is a Dangerous Game
- Linux vs. QNX in Safety-Critical Systems: A Pragmatic View
- Is Rust ready for safety related applications?
- The open projects rethinking safety culture
- RISC-V Summit Europe 2025: What to Expect from Codethink
- Cyber Resilience Act (CRA): What You Need to Know
- Podcast: Embedded Insiders with John Ellis
- To boldly big-endian where no one has big-endianded before
- How Continuous Testing Helps OEMs Navigate UNECE R155/156
- Codethink’s Insights and Highlights from FOSDEM 2025
- CES 2025 Roundup: Codethink's Highlights from Las Vegas
- FOSDEM 2025: What to Expect from Codethink
- Codethink/Arm White Paper: Arm STLs at Runtime on Linux
- Speed Up Embedded Software Testing with QEMU
- Open Source Summit Europe (OSSEU) 2024
- Watch: Real-time Scheduling Fault Simulation
- Improving systemd’s integration testing infrastructure (part 2)
- Meet the Team: Laurence Urhegyi
- A new way to develop on Linux - Part II
- Shaping the future of GNOME: GUADEC 2024
- Developing a cryptographically secure bootloader for RISC-V in Rust
- Meet the Team: Philip Martin
- Improving systemd’s integration testing infrastructure (part 1)
- A new way to develop on Linux
- RISC-V Summit Europe 2024
- Safety Frontier: A Retrospective on ELISA
- Codethink sponsors Outreachy
- The Linux kernel is a CNA - so what?
- GNOME OS + systemd-sysupdate
- Codethink has achieved ISO 9001:2015 accreditation
- Outreachy internship: Improving end-to-end testing for GNOME
- Lessons learnt from building a distributed system in Rust
- FOSDEM 2024
- QAnvas and QAD: Streamlining UI Testing for Embedded Systems
- Outreachy: Supporting the open source community through mentorship programmes
- Using Git LFS and fast-import together
- Testing in a Box: Streamlining Embedded Systems Testing
- SDV Europe: What Codethink has planned
- How do Hardware Security Modules impact the automotive sector? The final blog in a three part discussion
- How do Hardware Security Modules impact the automotive sector? Part two of a three part discussion
- How do Hardware Security Modules impact the automotive sector? Part one of a three part discussion
- Automated Kernel Testing on RISC-V Hardware
- Automated end-to-end testing for Android Automotive on Hardware
- GUADEC 2023
- Embedded Open Source Summit 2023
- Full archive