The past few weeks the GDP delivery team together with some key contributors, have been working on a not very visible but still important change. The GDP project has created the basis for turning the GDP release based delivery model to a "rolling" one. My colleagues will provide in a coming post the technical details behind this change. I want to provide a higher level view of what is happening and why.
Some background
GDP was born as a "demo" project. The main goal was to provide a platform to show the software components for automotive that the different GENIVI Expert Groups were developing. This was done through a delivery model focused on publishing a stable and easy to consume version of the project every few months, a major release.
Strictly speaking, the GDP is a derivative. It is based on poky and uses Yocto tools to "create" the Linux based platform, adding the different components developed by the GENIVI Alliance together with upstream software. For the defined purpose, the release centric model works fine, especially if you concentrate your effort in very specific areas of the software stack with a small number of dependencies on the other areas, and a limited number of contributions and environments where the system should work. During 2016, GDP has grown significantly. We have more software, more contributors, more components and more target boards to take care of. Although the above model has not been not challenged yet, it was just a matter of time. As explained in two previous posts [1] [2], the GDP is moving from being a Demo to a Development Platform. Changing the mission means changing the goals and the target group, which implies the need to adjust the deliverable to meet the new expectations.
So, right after the 14th AMM, the Delivery Team decided to change the delivery model to better meet the new mission, providing developers the newest possible software with an increasing quality threshold. At the same time, in order to increase the number of contributors, the GDP needs to provide a new solid platform every once in a while. That should be done through a solid release.
What is a rolling delivery model?
The key idea behind a modern delivery release model is to ensure that the transition from one stable release to the next one takes an affordable effort. I will display an example to picture the idea
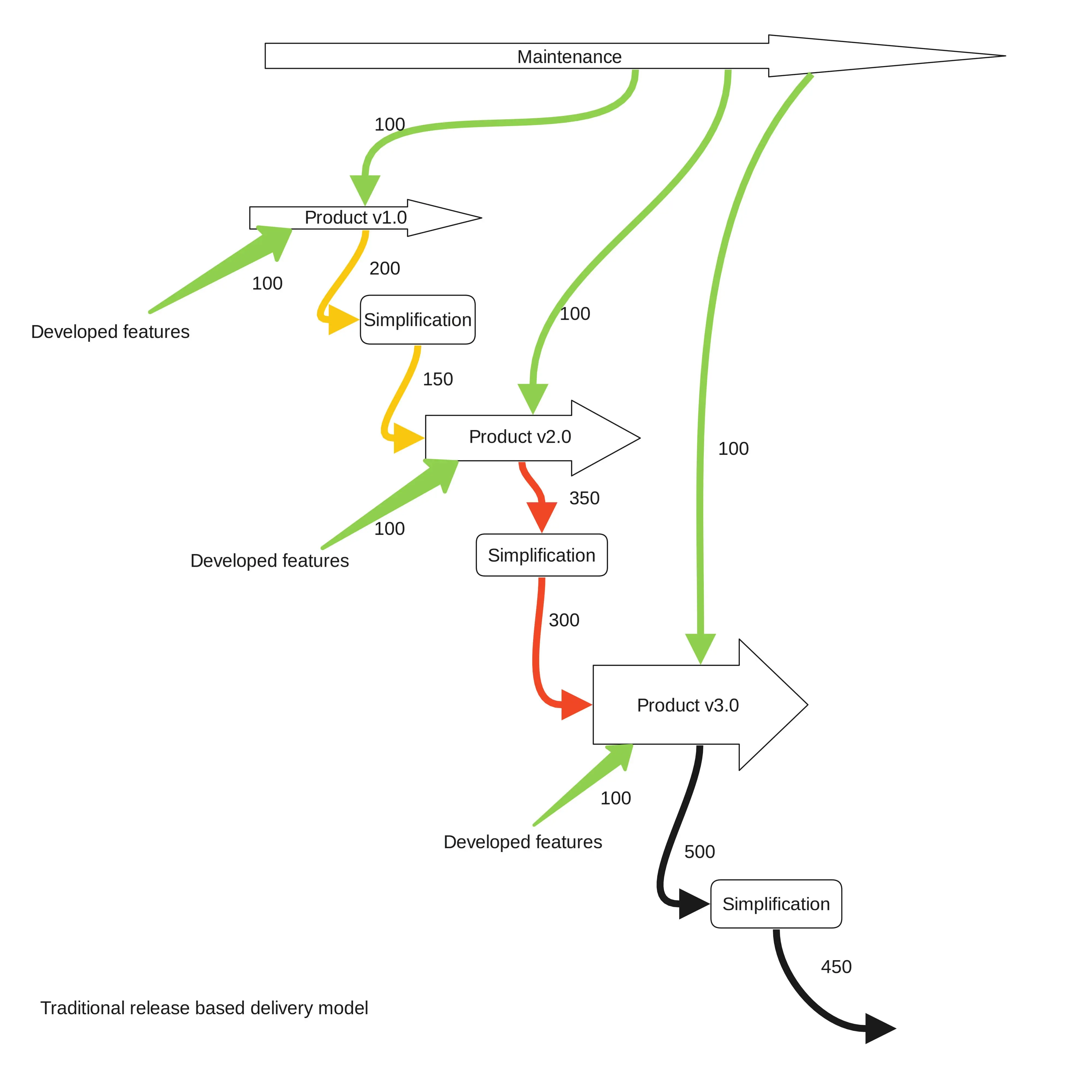
Problem statement
Imagine an organization that publishes one release per year. Let's assume that a particular release included 100 patches developed by employees and, during the lifetime of the release (1 year too), another 100 patches were added to the product as bug fixes and updates. At the end of the release lifetime, the product includes 200 patches that define the value the product provides to customers and users.
Either for technical or business reasons, a year later it is time to upgrade. Our organization has to create a new Linux based system with newer upstream code and they have to integrate the patches from the previous release plus the updates and bug fixes developed for the coming release.
After a simplification process done by engineers, the number of patches needed to be integrated in this newer base system is reduced to 150. The organization also wants to add to this new release another 100 patches that represent the new features they have been developing during the last year for this new version. The delivery team now has to integrate 250 patches in the new base system, 150 of them coming from the previous release. One might think that the effort required to do this is 2.5 times the effort invested in the previous release. Maybe you think that the effort is not so high since some of the patches have been developed thinking about the new base system. There are many other considerations like this one that might affect the initial estimation. This example is obviously a simplification.
However any experienced release manager will tell you that moving patches integrated in an older system base onto a newer one (forward-porting) requires additional effort, beyond a linear relation with the number of patches. Forward-porting is the "road to hell". Iterate this example a few times and you will understand why there are so many organizations out there that have as many people focusing on delivery as they have in development. They migrated to Linux base system keeping the traditional delivery model they had while working with closed source software.
Possible solutions
One of the paths to improve the situation is upstreaming those changes that affect generic components. Some companies also upstream their new features early in their development process, generally looking for wider testing, or after they have been released to customers, to increase adoption and reduce future maintenance effort. This is definitely a must do.
From the delivery perspective, the most popular way to tackle the problem though is reducing the release cycle, so the number of patches to forward-port in each release is smaller. The development time and the maintenance cycles are also smaller. The same applies to the complexity of the forward-porting activities. "Jumping" from one release to the next one is easier to do. Add automation of repetitive tasks to this recipe and you feel you have a win.... for some time.
The journey through the "road to hell" becomes more comfortable, but our organization is still getting burned, even in the case that our customers and ourselves can digest releasing frequently. We all know how expensive and stressful a release might become.
The most suitable option to achieve sustainability while scaling up the amount of software an organization can manage without releasing more often than your market can digest is to change your delivery model. Rolling delivery models are a serious attempt to solve this problem, putting integration as the central element instead of the software itself.
This model is not new. Gentoo has been doing it forever, but it was Arch Linux who implemented it in a way that immediately attracted the attention of thousands of developers. Still it was a model with no hope beyond hardcore Linux developers. OpenSUSE brought this model to a new level by implementing a process whose output was stable enough for a much wider audience, and compatible with the release of a more stable and a commercial releases. Nowadays there are other interesting examples out there that commercial organizations can learn from.
What is a rolling model?
It is still hard to define but essentially it is a process in which ideally you have one continuous integration (CI) pipeline as the one and only entry point for the software you plan to ship. Releases then become snapshots of all or part of the software already integrated after going through a specific stabilization, deployment and release process.
So ideally, if you release a portfolio, you integrate only once, reducing significantly the costs of having different engineers working on different versions of the same software and forward-porting, among other benefits. A rolling delivery model is then a lot more than a continuous integration chain, although that is the key point. Please have in mind that this is an oversimplification. This description doesn't go into detail on other key aspects like maintenance cycles, how upstreaming affects the process, strategies towards updating the released products, etc.
A transformation process that takes an organization from a release centric model to a rolling one is about doing less and doing it faster, so less people can handle more software with less pain, allowing more people to concentrate in creating value, developing new and better software instead of just shipping it.
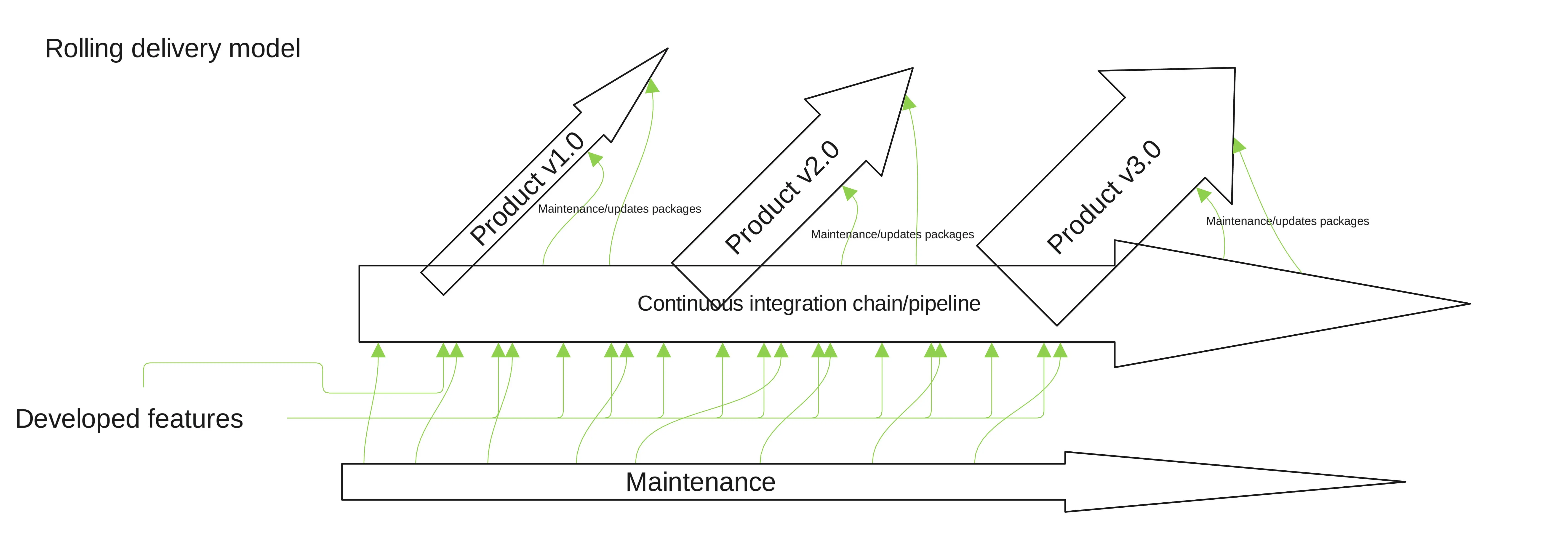
Back to GENIVI
Moving from a release centric to a rolling model is hard work. Frequently it is easier to start all over again. Since the GDP is still a relatively small project, we can afford going through the transformation process step by step.
The first stage has been creating that single integration chain and treating GDP-ivi9, our latest release, and those that follow it, as a deliverable of what we call today Master. Ideally, no single patch will be added directly to the release branches. They should come from Master. That way, we reduce (ideally to zero) the effort of forward-porting of patches while putting in the hands of our contributors the latest software on a regular basis.
To do so, we are in the process of adapting our simple processes and CI system to the new model, GDP repository structure, the wiki contents, the task management structures, several key policies, our communication around the project...
The GDP will face a very interesting challenge since this model needs to be proven successful for a derivative. If we are able to move fast enough, it will come the time in which we will need to decide if GDP keeps being a derivative or it becomes upstream, that is, either GDP limits the delivery speed based on the Poky release cycle, or we work upstream with the Yocto project to increase our delivery speed. That is a good problem to have, isn't it?
If (almost) everything goes right, after adding a few needed services in GENIVI's infrastructure and ensuring the updated software is in compliance with selected verification criteria, the same number of people will be able to manage and deliver more software. And once the new processes become more stable, automation will not just increase efficiency, it will boost the project by allowing GENIVI to achieve goals that only big organizations with large delivery teams can do. This is the kind of transformation that takes time to consolidate, but has a huge impact. Based on my experience, I believe that if GENIVI is able to sustain this effort and keep a clear direction the next couple of years, the benefits of moving towards a rolling model will be noticeable even outside the industry.
Article originally published on the GENIVI blog on July 6th 2016.
Other Content
- Assessing the reproducibility workflow in freedesktop-sdk
- Deep Dive into Upstream RISC-V Boot Chain
- Porting an Automotive Operating System to RISC-V
- Understanding Codethink's IEC 61508 Mapping for the Eclipse Trustable Software Framework
- Resisting Hyrum's Law with Private Constructors in Python
- FOSDEM 2026
- Building on STPA: How TSF and RAFIA can uncover misbehaviours in complex software integration
- Adding big‑endian support to CVA6 RISC‑V FPGA processor
- Bringing up a new distro for the CVA6 RISC‑V FPGA processor
- Externally verifying Linux deadline scheduling with reproducible embedded Rust
- Engineering Trust: Formulating Continuous Compliance for Open Source
- Why Renting Software Is a Dangerous Game
- Linux vs. QNX in Safety-Critical Systems: A Pragmatic View
- Is Rust ready for safety related applications?
- The open projects rethinking safety culture
- RISC-V Summit Europe 2025: What to Expect from Codethink
- Cyber Resilience Act (CRA): What You Need to Know
- Podcast: Embedded Insiders with John Ellis
- To boldly big-endian where no one has big-endianded before
- How Continuous Testing Helps OEMs Navigate UNECE R155/156
- Codethink’s Insights and Highlights from FOSDEM 2025
- CES 2025 Roundup: Codethink's Highlights from Las Vegas
- FOSDEM 2025: What to Expect from Codethink
- Codethink/Arm White Paper: Arm STLs at Runtime on Linux
- Speed Up Embedded Software Testing with QEMU
- Open Source Summit Europe (OSSEU) 2024
- Watch: Real-time Scheduling Fault Simulation
- Improving systemd’s integration testing infrastructure (part 2)
- Meet the Team: Laurence Urhegyi
- A new way to develop on Linux - Part II
- Shaping the future of GNOME: GUADEC 2024
- Developing a cryptographically secure bootloader for RISC-V in Rust
- Meet the Team: Philip Martin
- Improving systemd’s integration testing infrastructure (part 1)
- A new way to develop on Linux
- RISC-V Summit Europe 2024
- Safety Frontier: A Retrospective on ELISA
- Codethink sponsors Outreachy
- The Linux kernel is a CNA - so what?
- GNOME OS + systemd-sysupdate
- Codethink has achieved ISO 9001:2015 accreditation
- Outreachy internship: Improving end-to-end testing for GNOME
- Lessons learnt from building a distributed system in Rust
- FOSDEM 2024
- QAnvas and QAD: Streamlining UI Testing for Embedded Systems
- Outreachy: Supporting the open source community through mentorship programmes
- Using Git LFS and fast-import together
- Testing in a Box: Streamlining Embedded Systems Testing
- SDV Europe: What Codethink has planned
- How do Hardware Security Modules impact the automotive sector? The final blog in a three part discussion
- How do Hardware Security Modules impact the automotive sector? Part two of a three part discussion
- How do Hardware Security Modules impact the automotive sector? Part one of a three part discussion
- Automated Kernel Testing on RISC-V Hardware
- Automated end-to-end testing for Android Automotive on Hardware
- GUADEC 2023
- Embedded Open Source Summit 2023
- Full archive